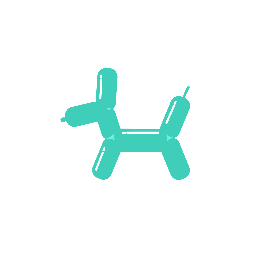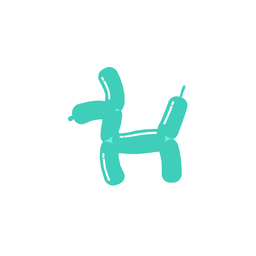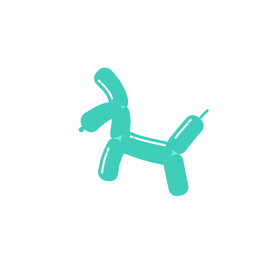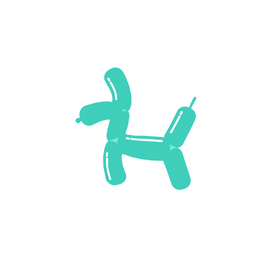
How does it work?
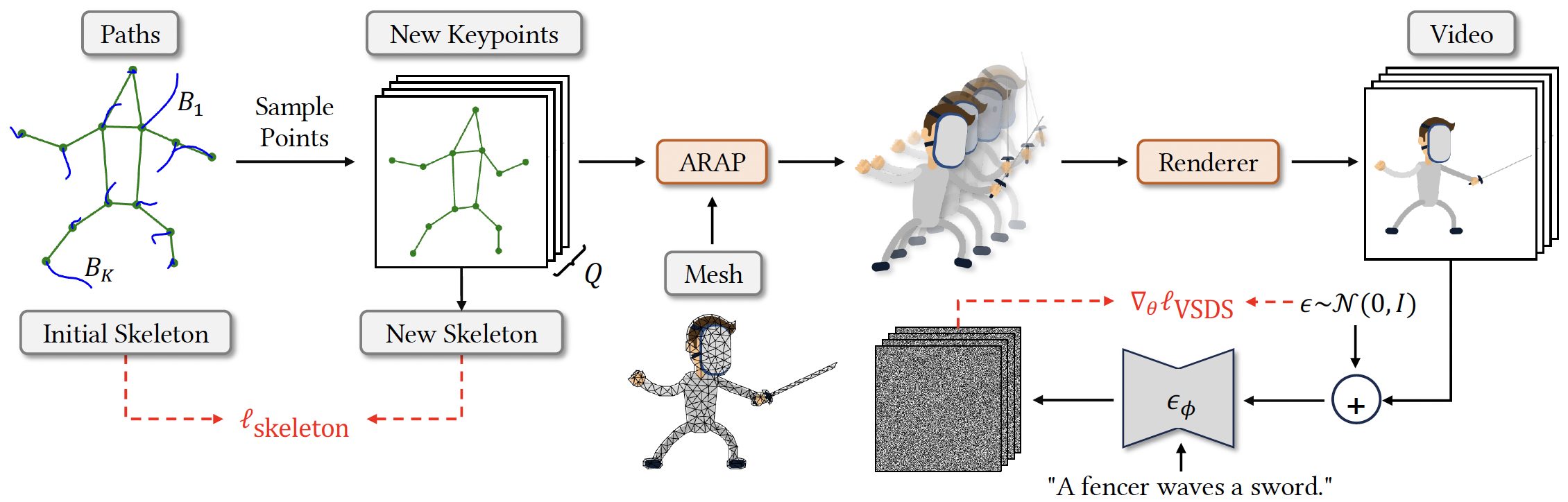
Given an initial clipart image with M keypoints, we initialize M corresponding cubic Bézier motion trajectories, parameterized by {c(i)}i=0M-1. For a sequence of N frames, keypoints are updated at each frame by sampling along these trajectories. The displaced keypoints are responsible for driving the ARAP shape deformation algorithm, which warps the object, represented by a triangle mesh, into new poses. This gives rise to a clipart animation, which is (optionally rasterized and) passed to a T2V model to compute the video SDS loss. To ensure motion coherence across all keypoints, a skeleton fidelity loss is also applied, penalizing changes in bone lengths over time.
Gallery
If images are not loaded properly, please refresh the page.


A man is scuba diving [..]

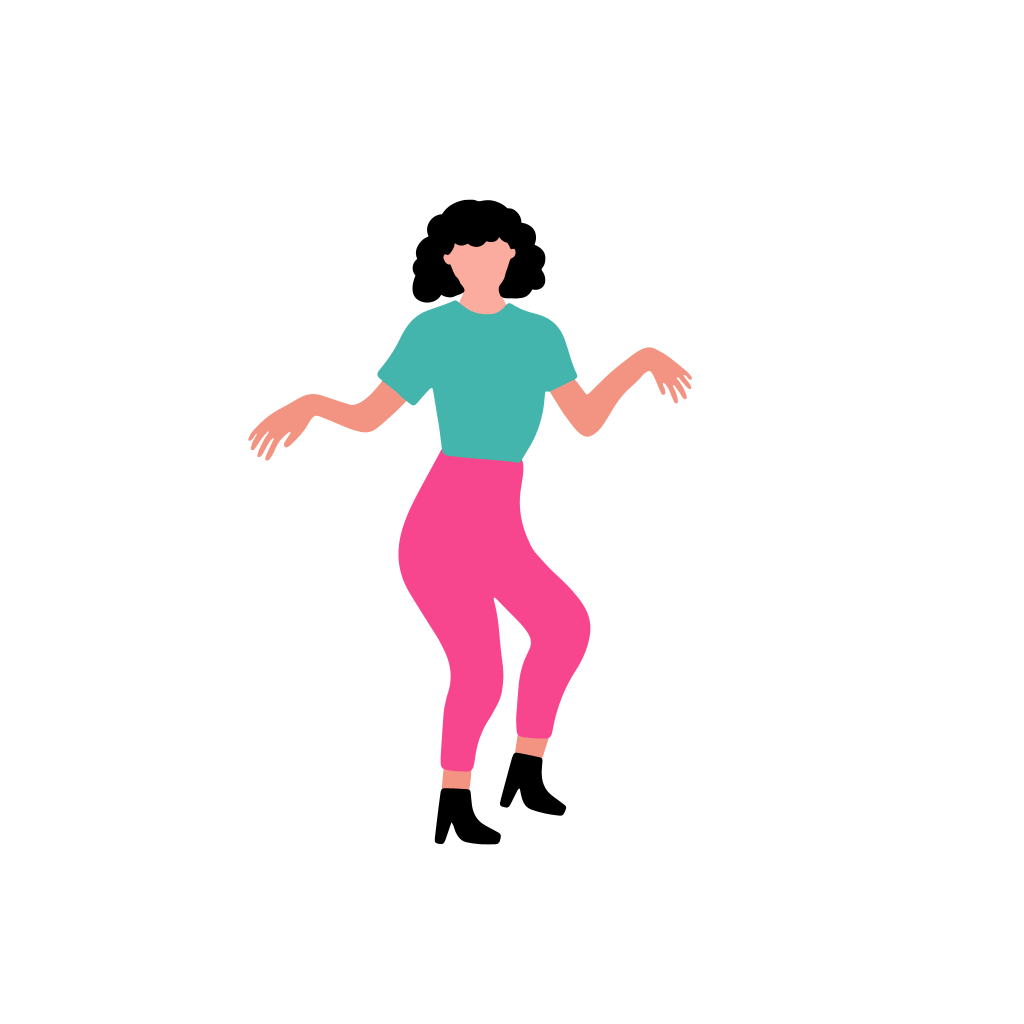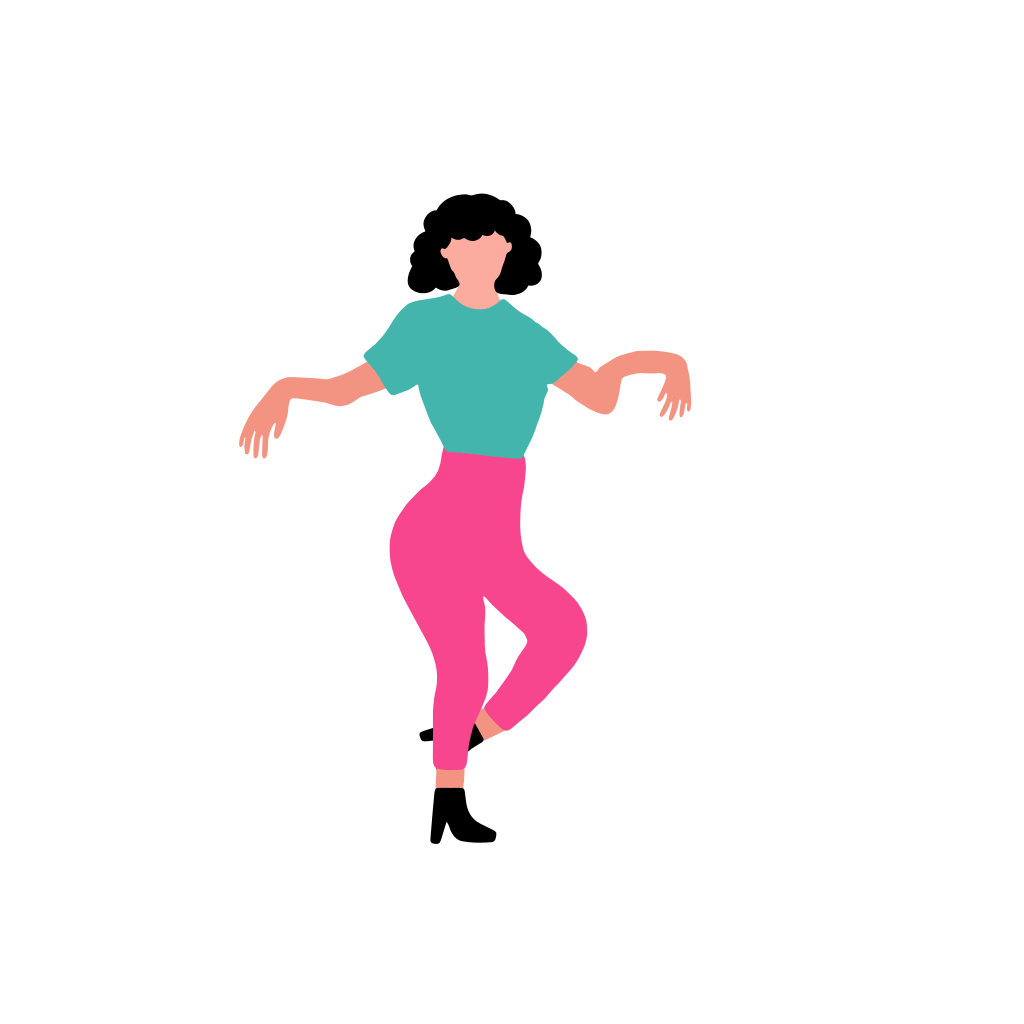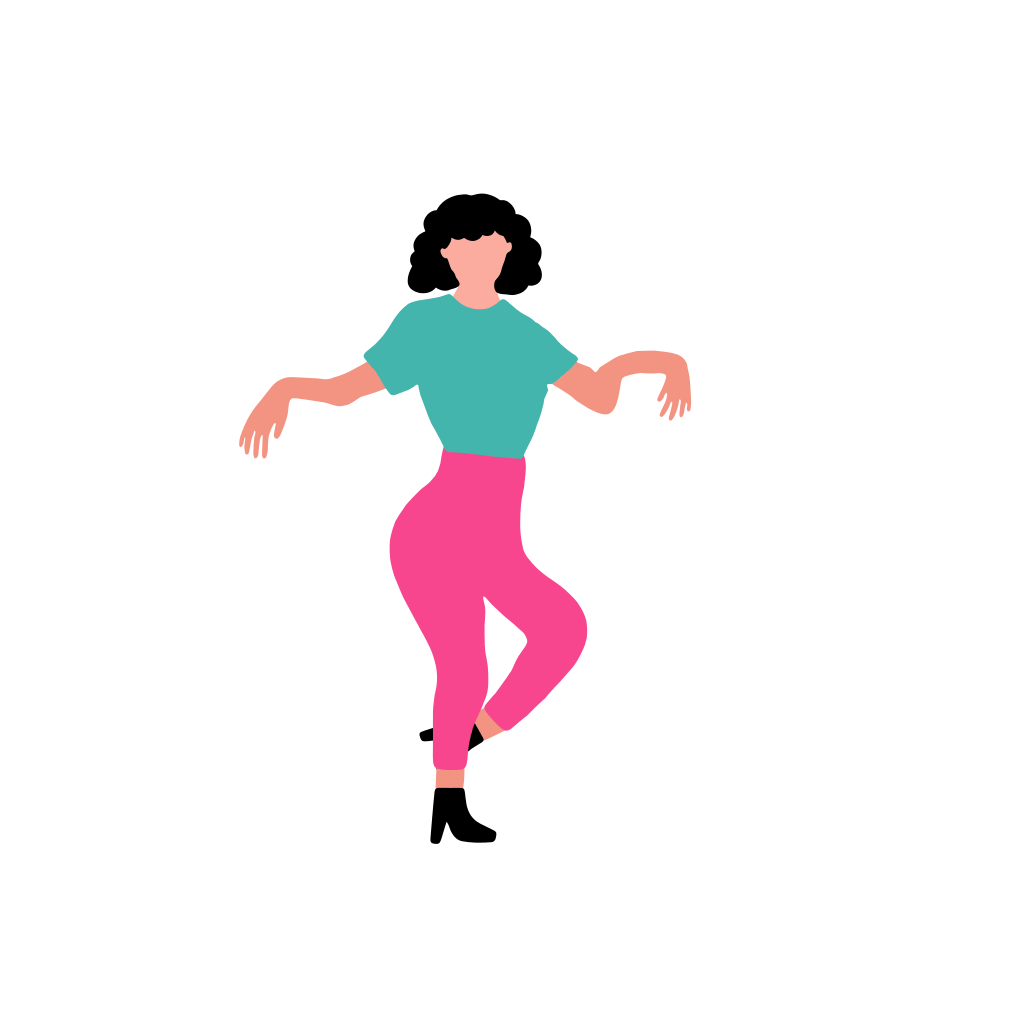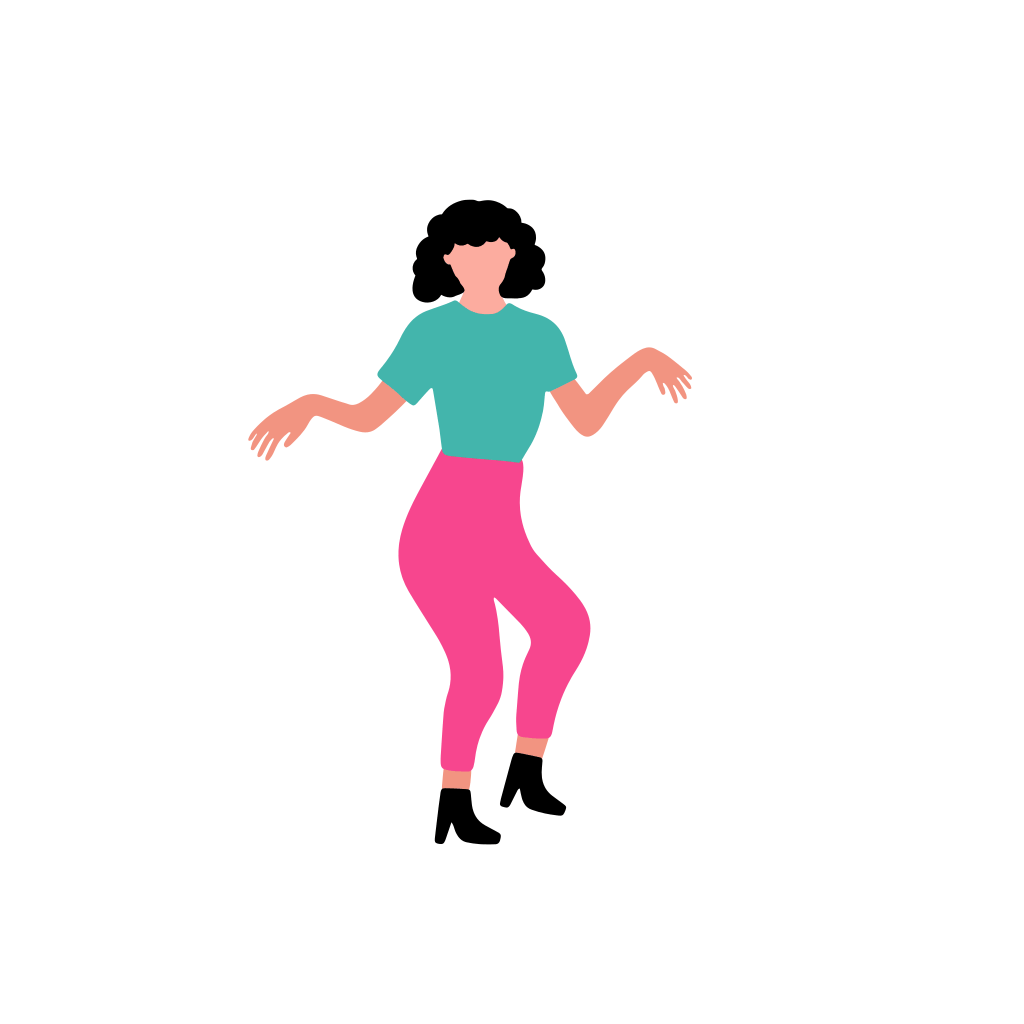
A woman dancer is dancing [..]


A bearded man is dancing [..]


A balloon floating in the [..]

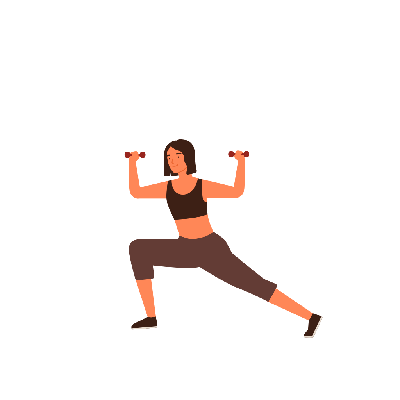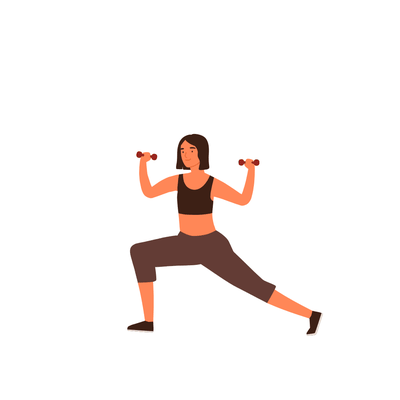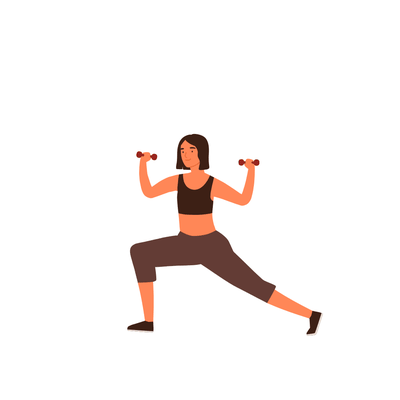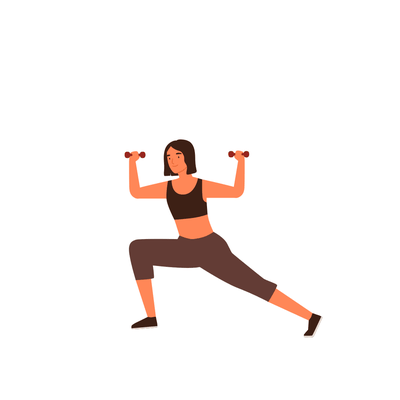
A young girl is exercising [..]


A young man is waving [..]


A cloud floats in the [..]


A flower sways its petals [..]


A crab is waving its [..]


A snowman is waving its [..]

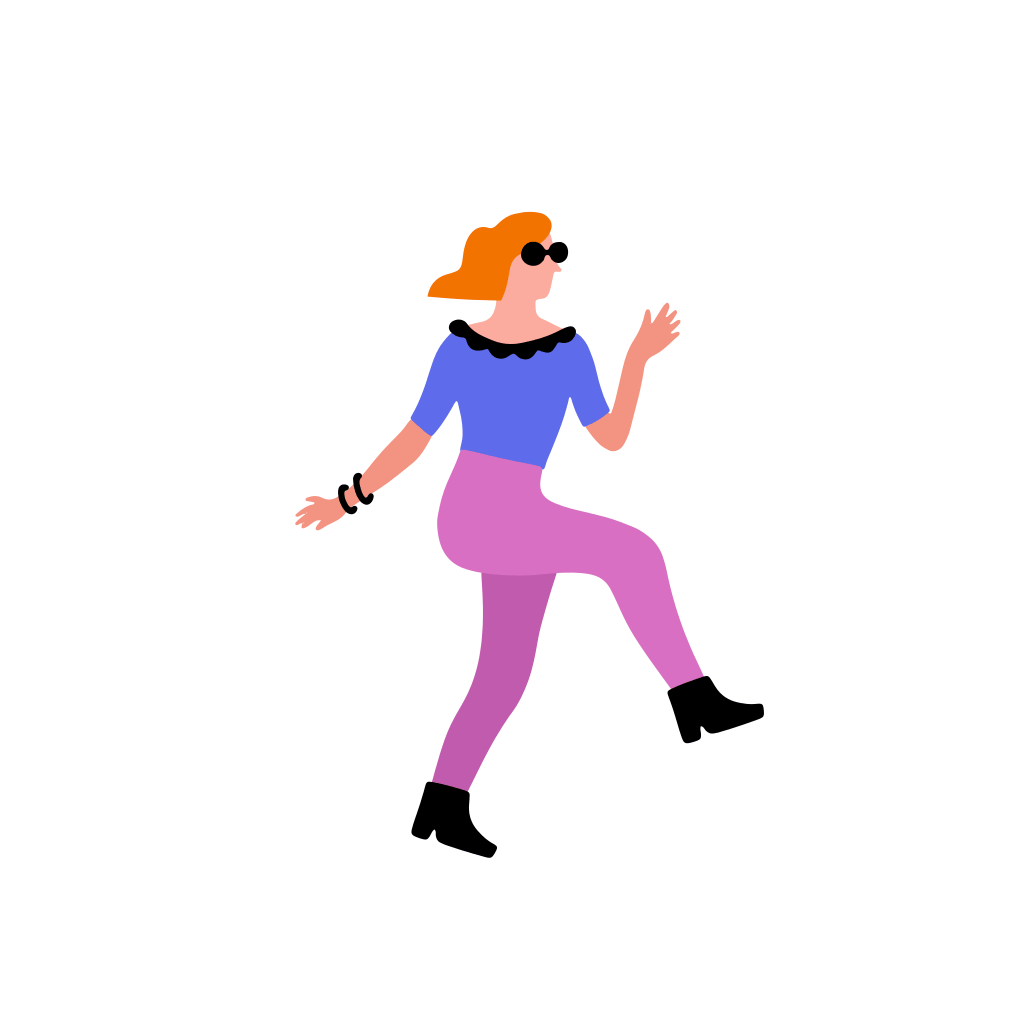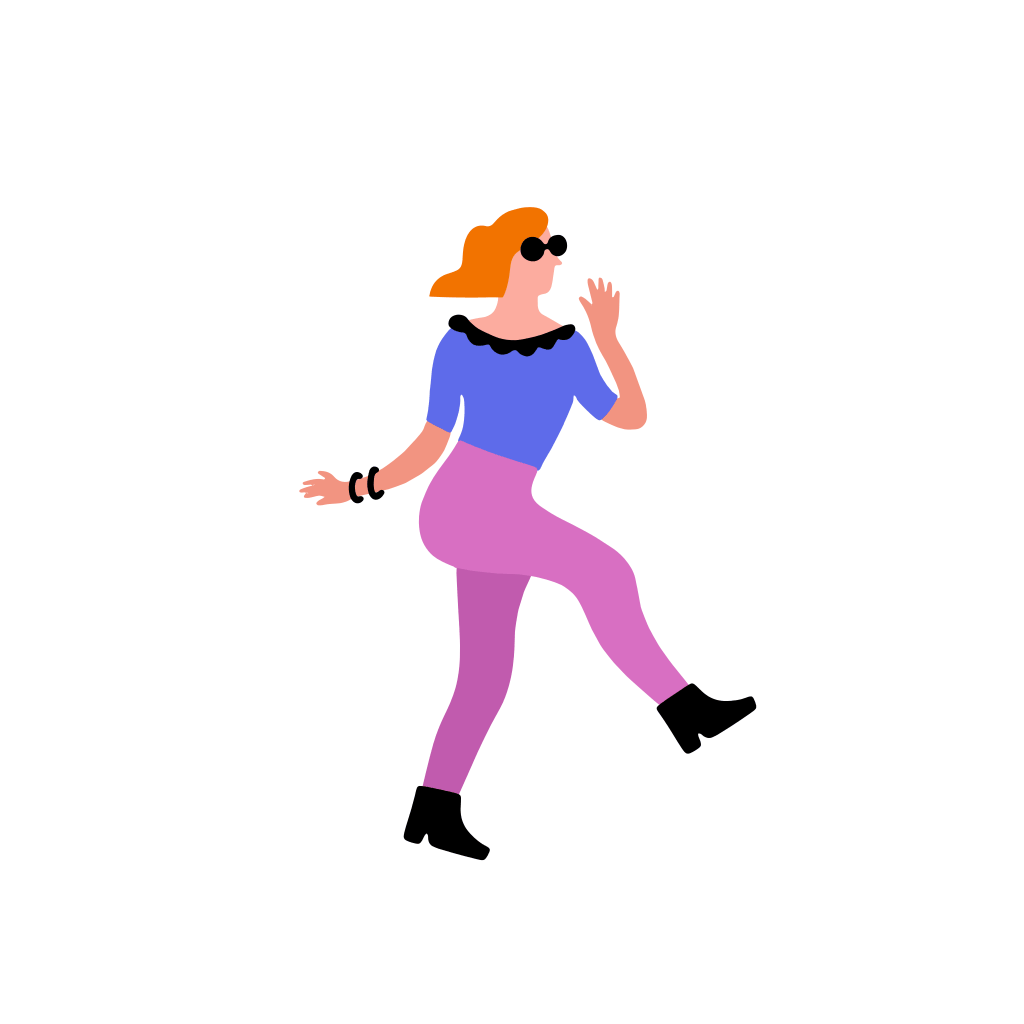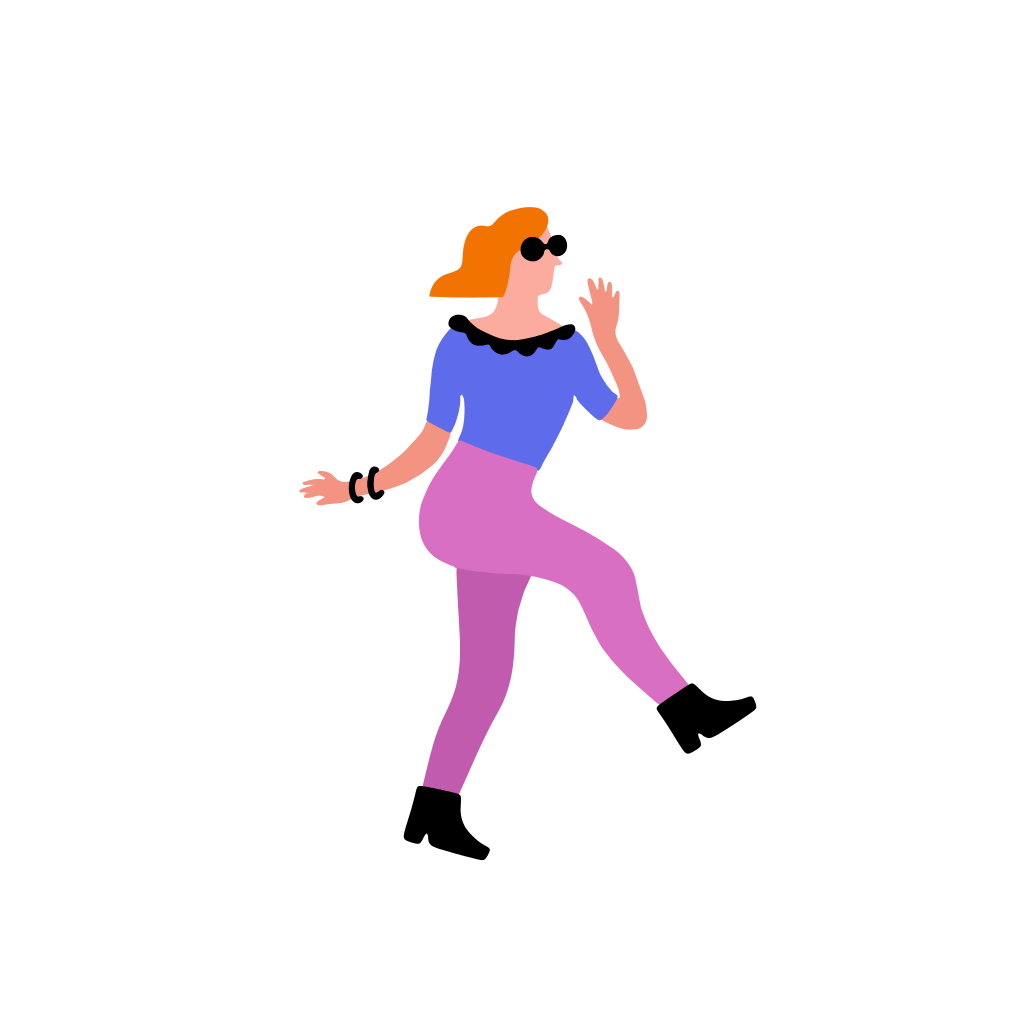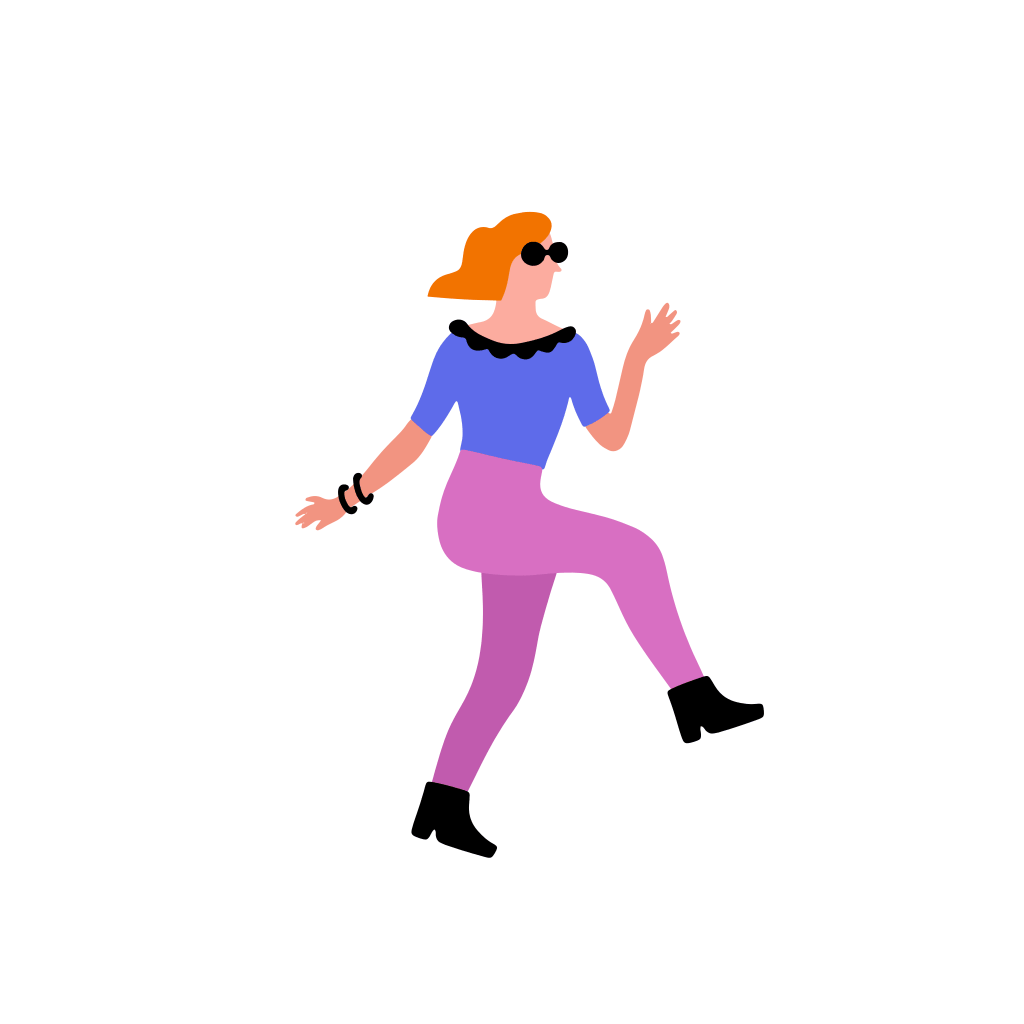
A woman dancer is dancing [..]


a cheerful green caterpillar is [..]

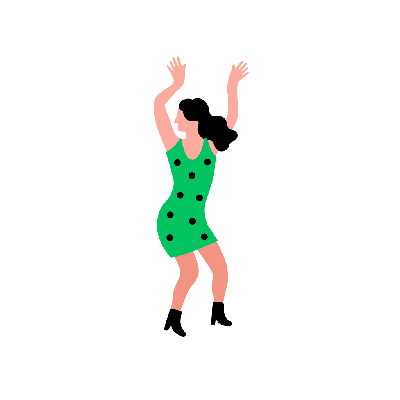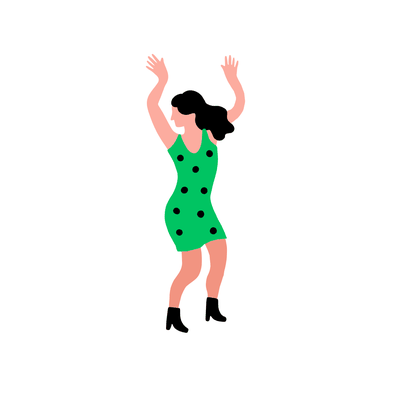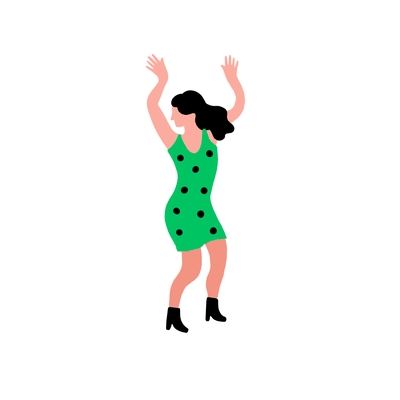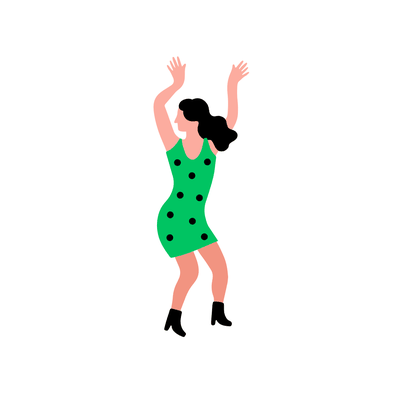
A woman in a green [..]


A bat is flapping its [..]


The Halloween ghost is cheering [..]

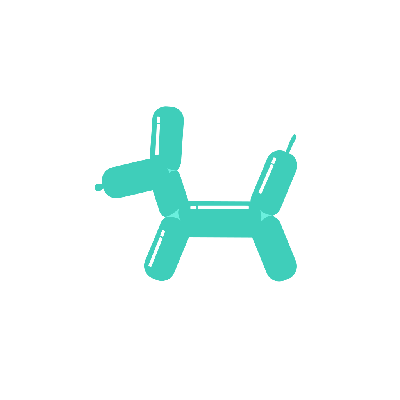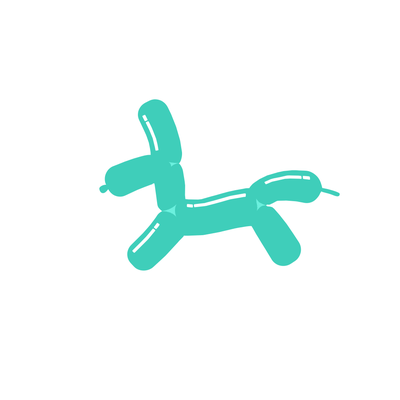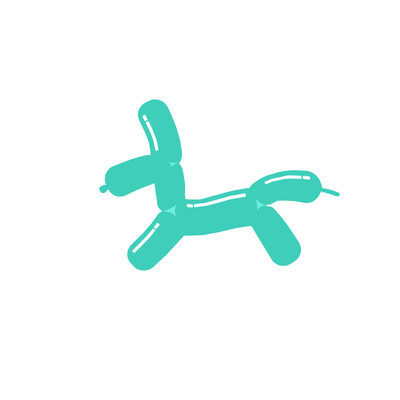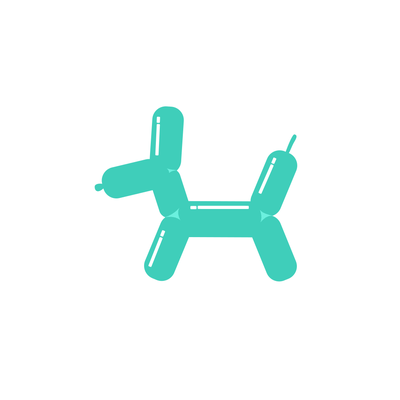
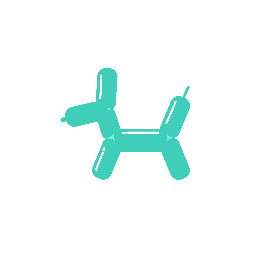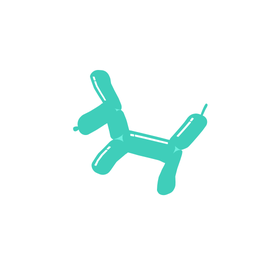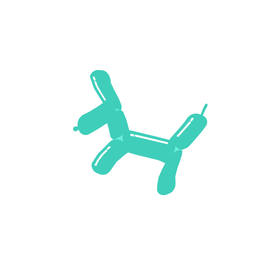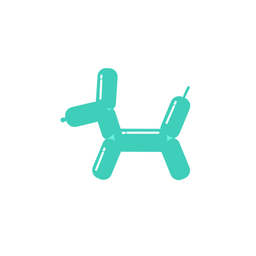
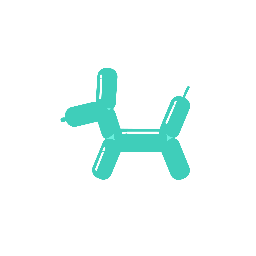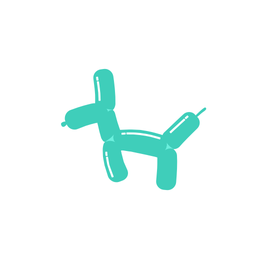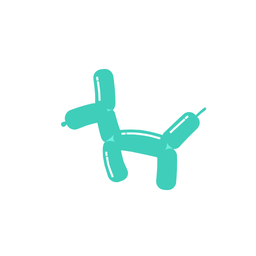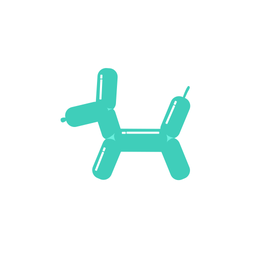
A galloping dog [..]


A young girl jumps up [..]

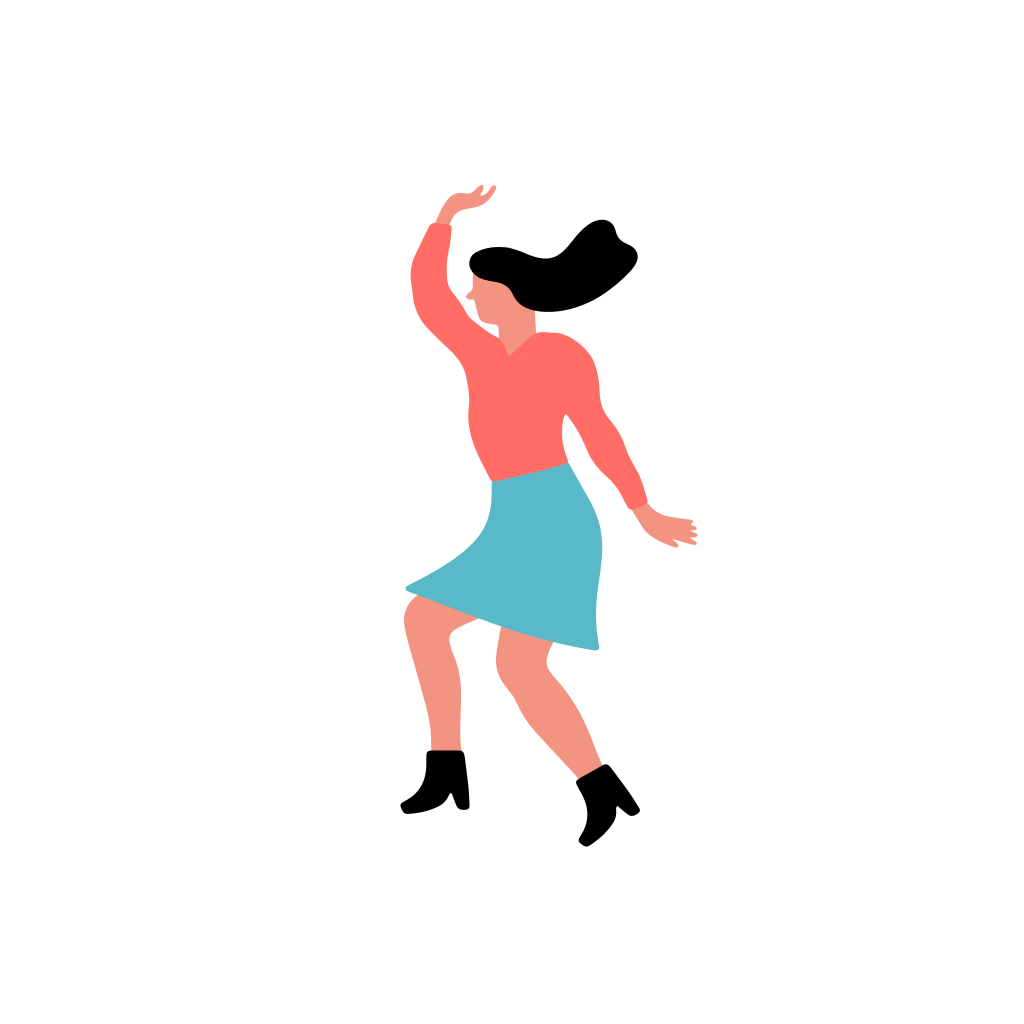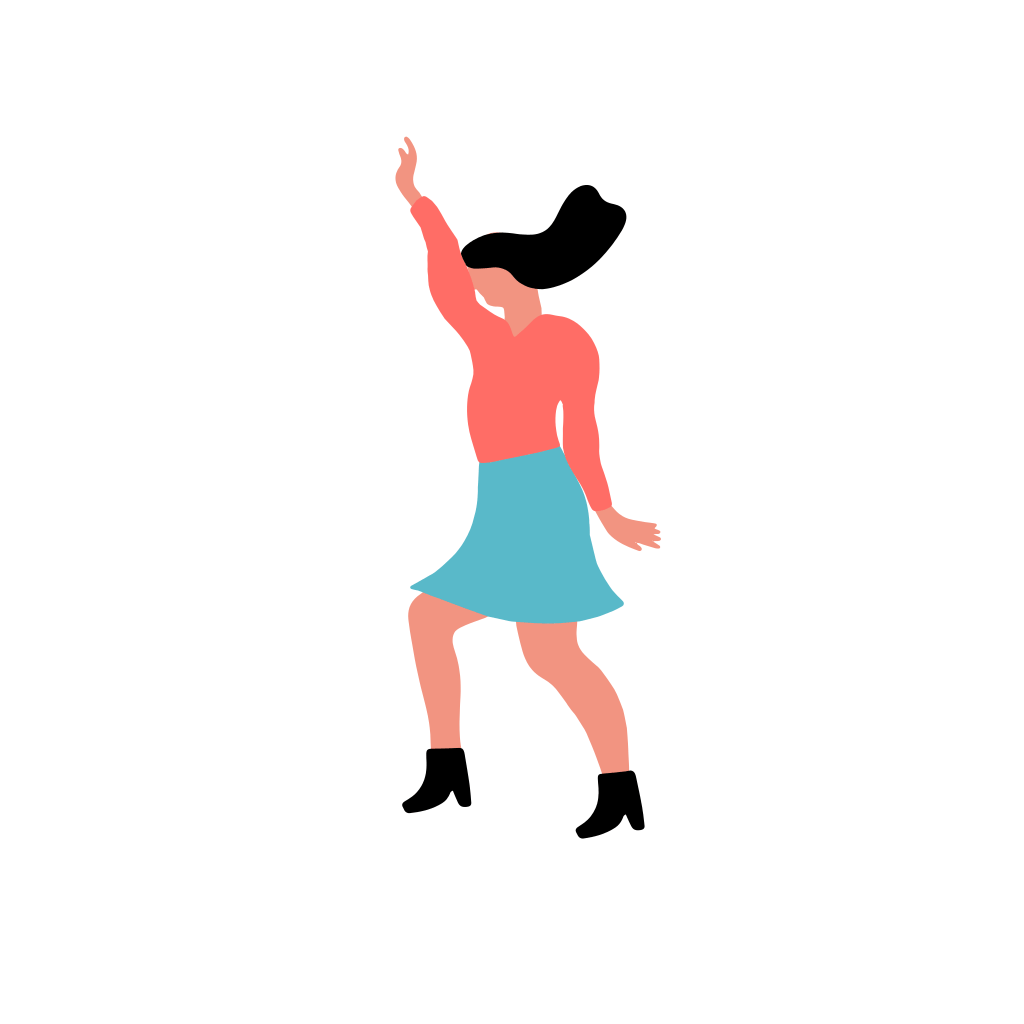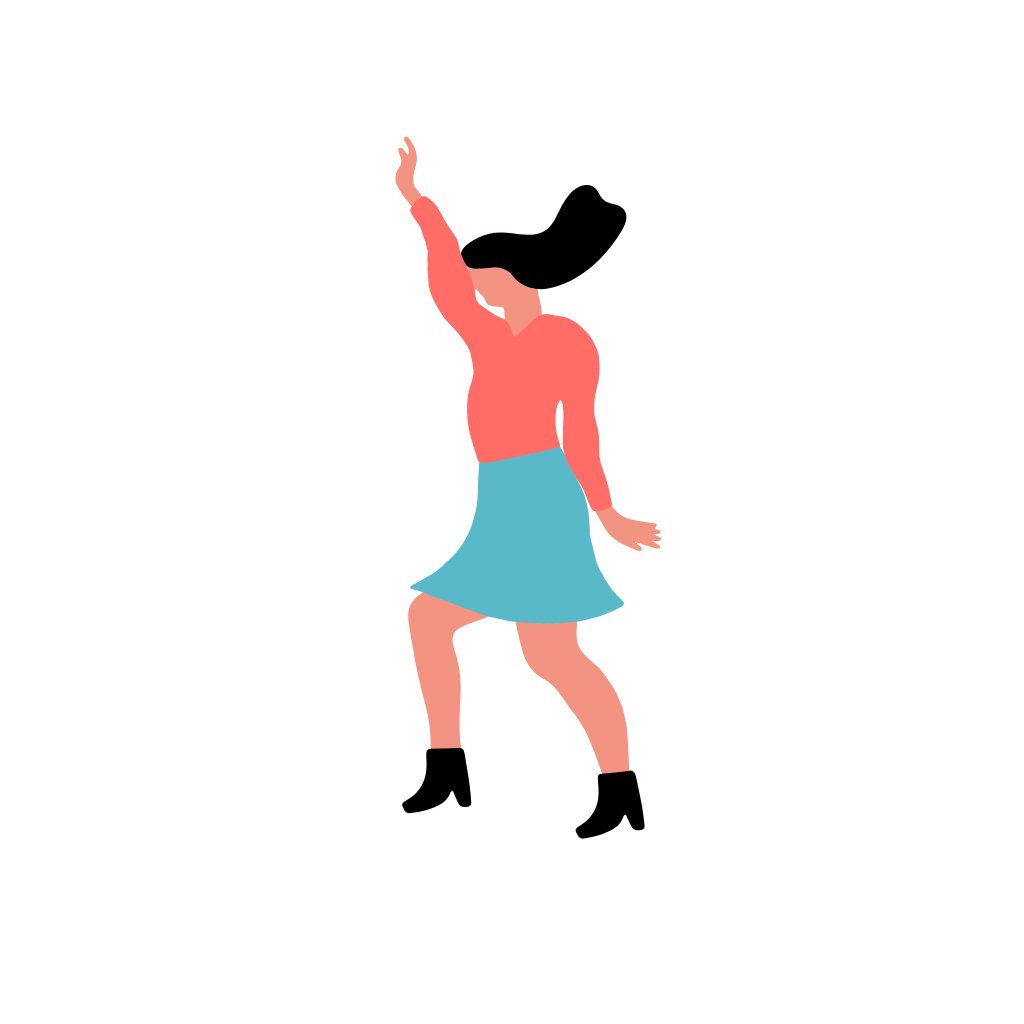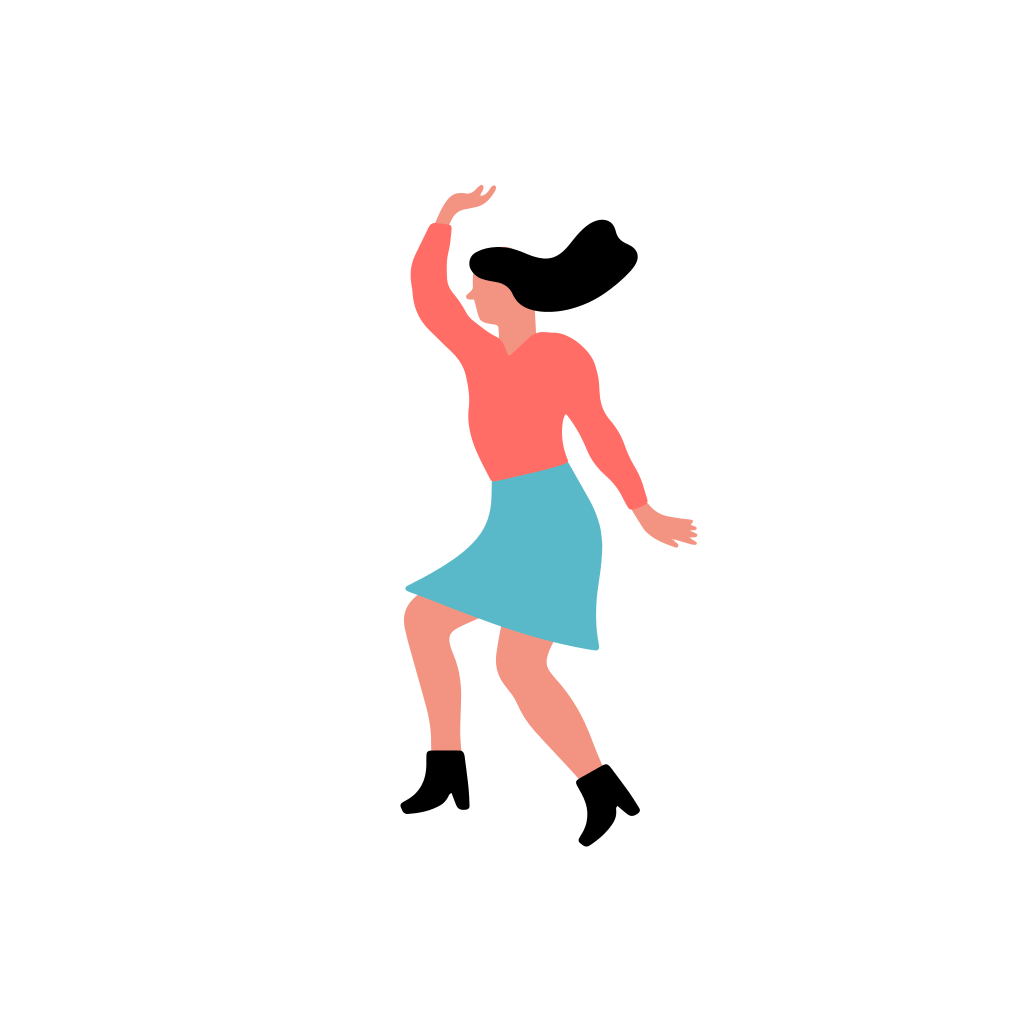
A woman in a flowing [..]


A fencer in en garde [..]


A kite is floating in [..]


A snail is moving. [..]


The parrot flapping its wings. [..]


A dolphin swimming and leaping [..]


A turtle floats up and [..]


A spider sways its legs. [..]


A young man jumps up [..]

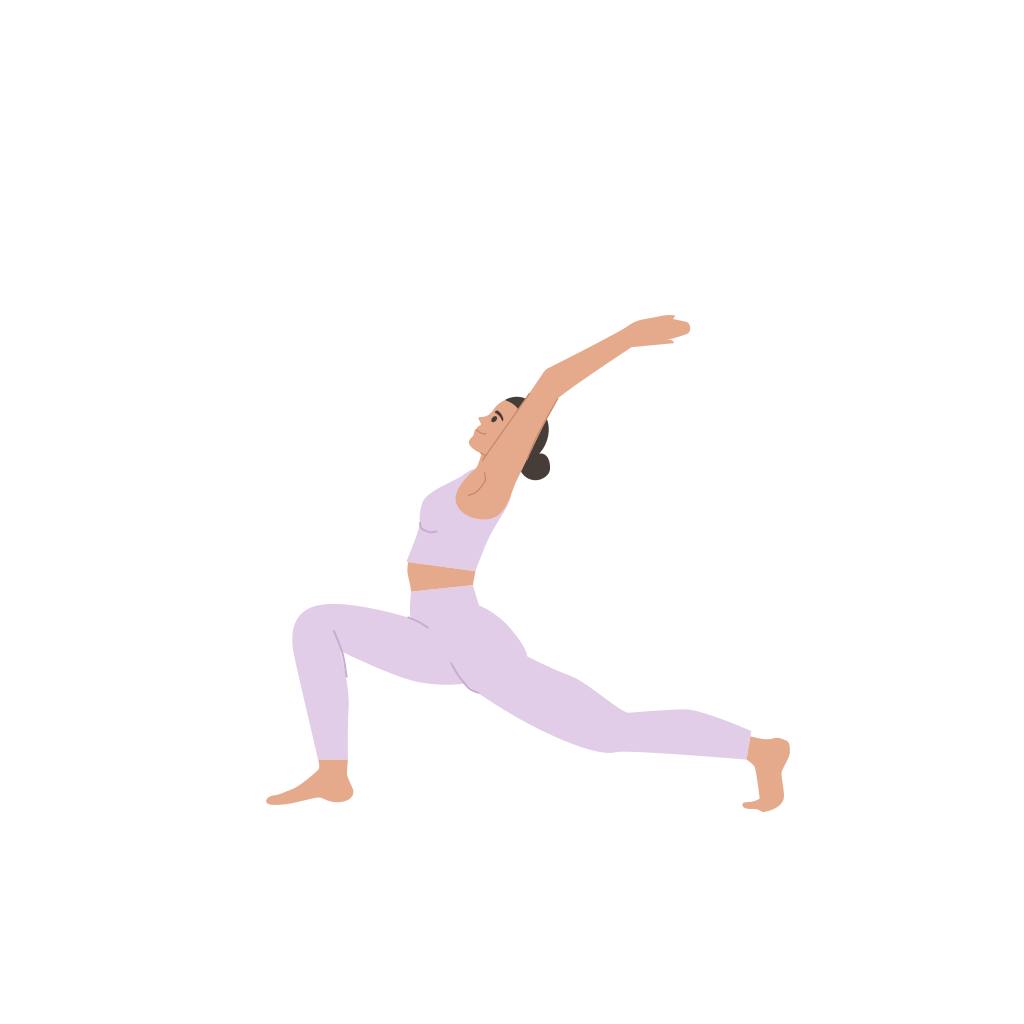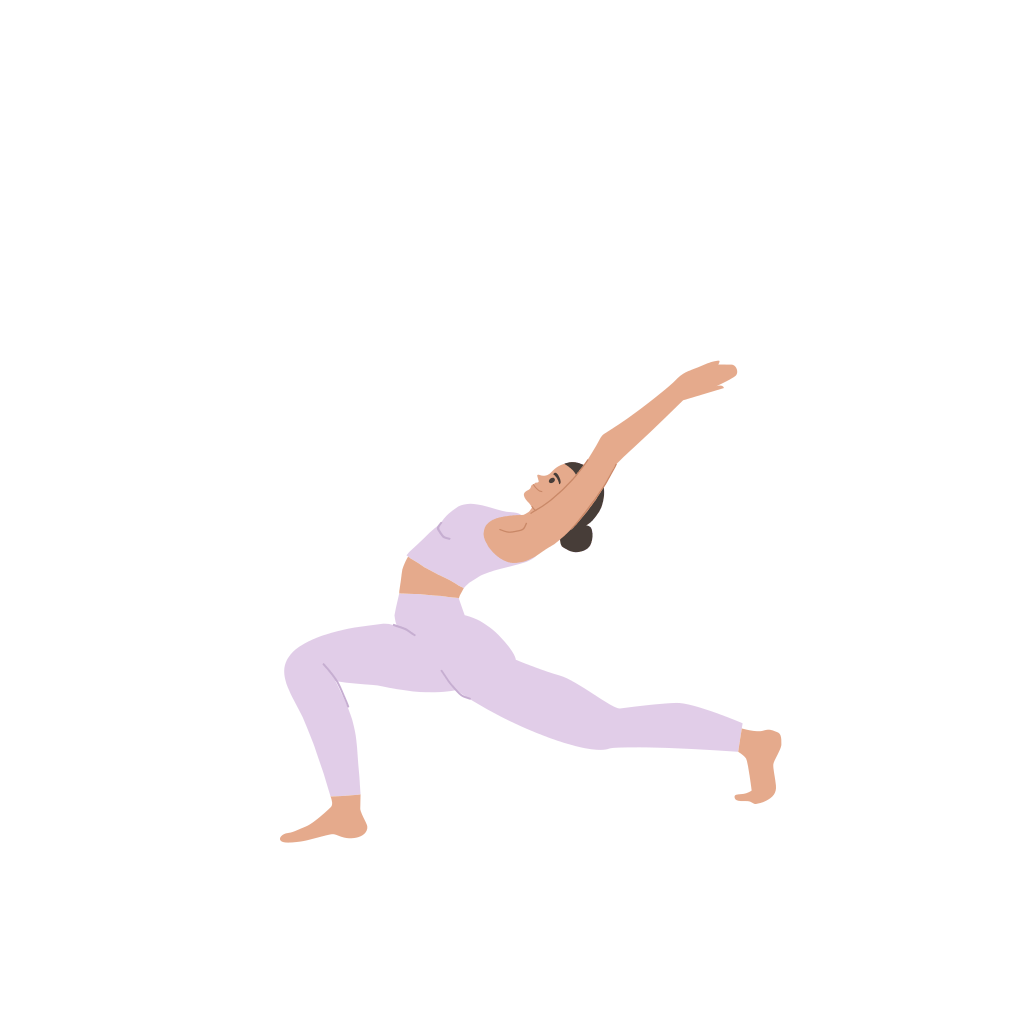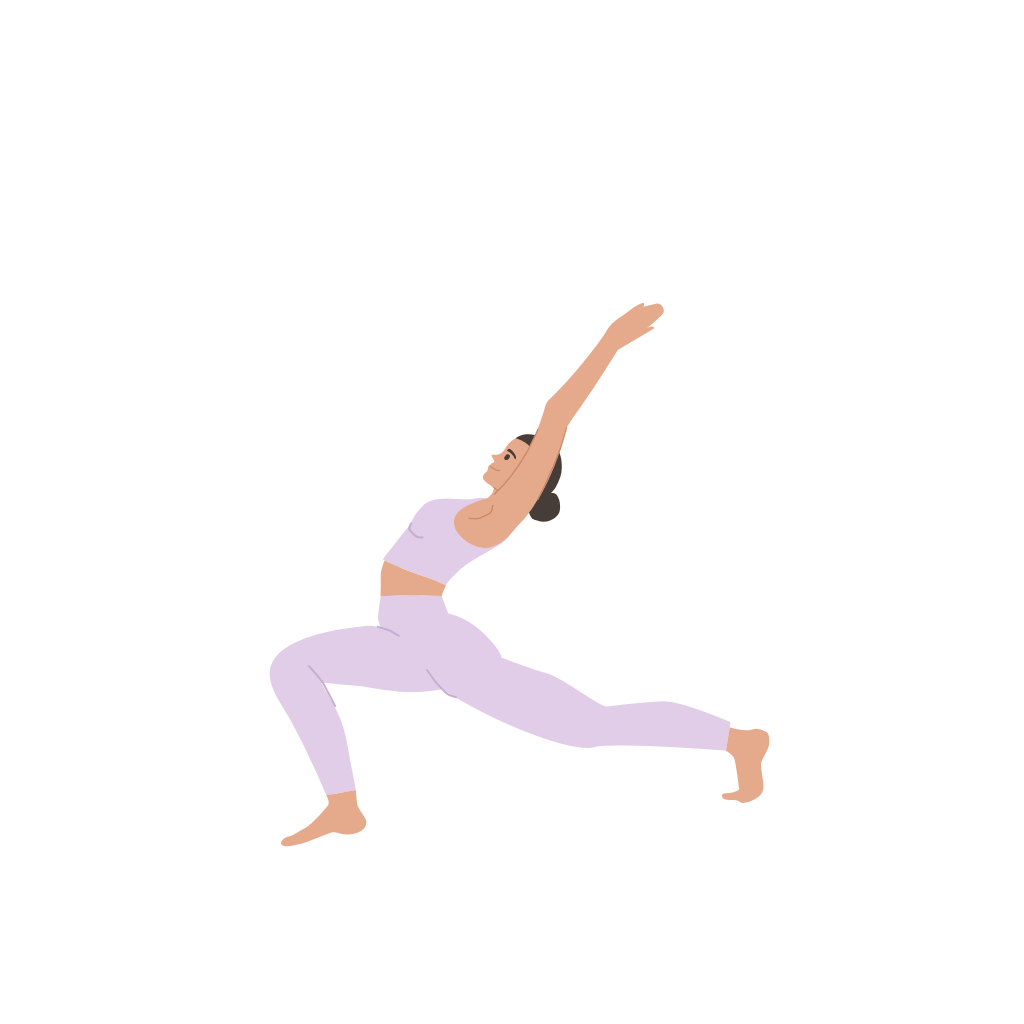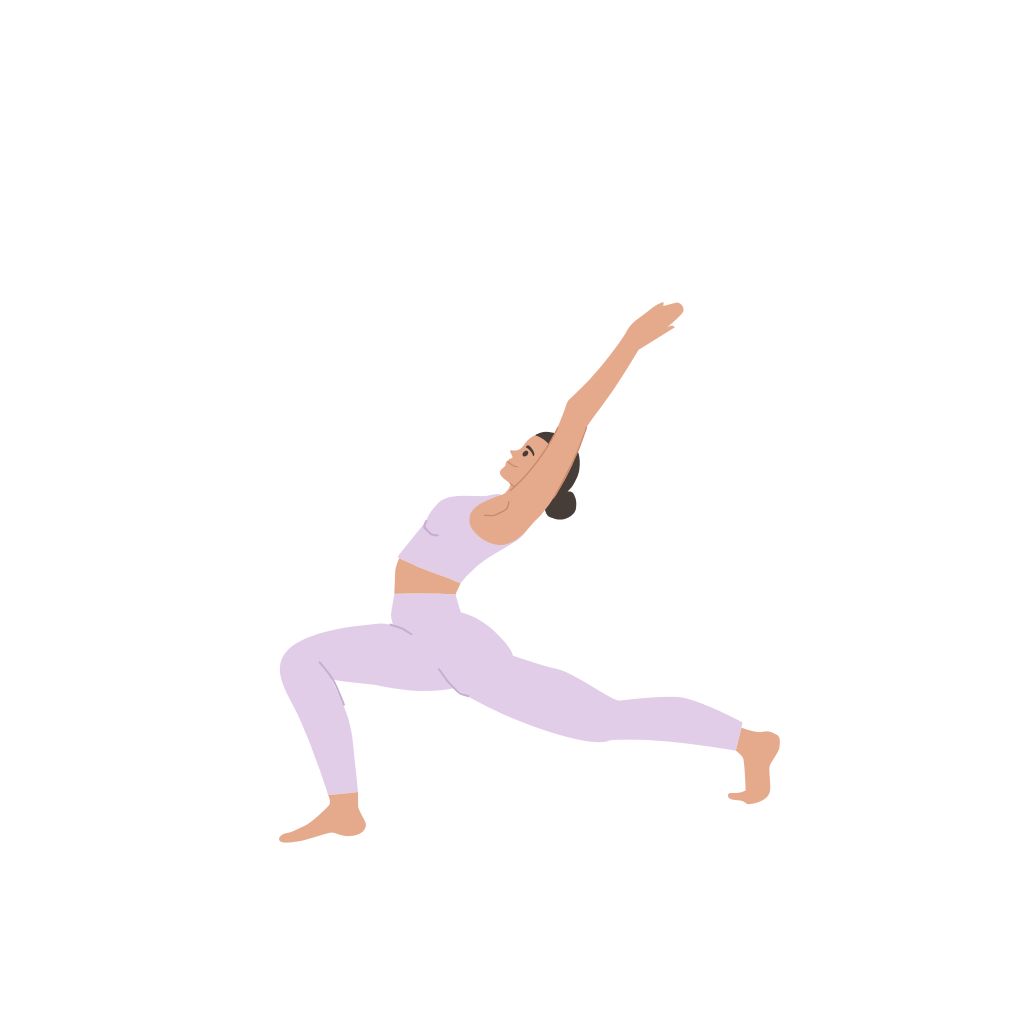
A woman is practicing yoga, [..]


A starfish is waving its [..]


The spaceship accelerates rapidly during [..]


A person wearing a pumpkin [..]


A surfer riding and maneuvering [..]


A parachute descending slowly and [..]


An octopus is swimming and [..]


Boxing guy is punching and [..]


A shrimp is swmming and [..]


A young girl is waving [..]


The man in demon costume [..]


The palm tree sways the [..]
Varying the Prompts
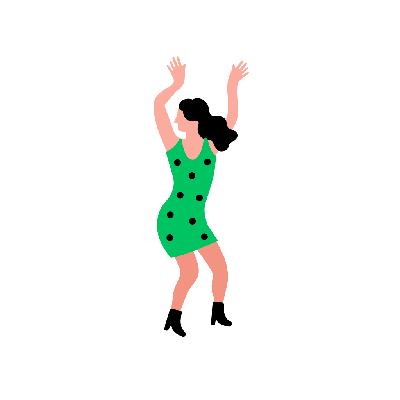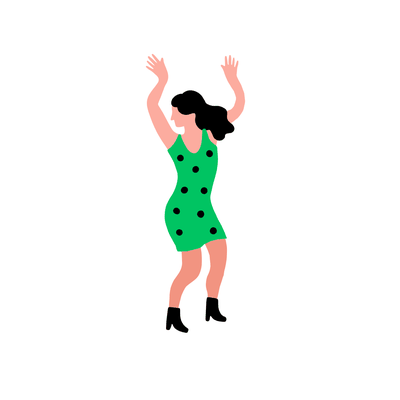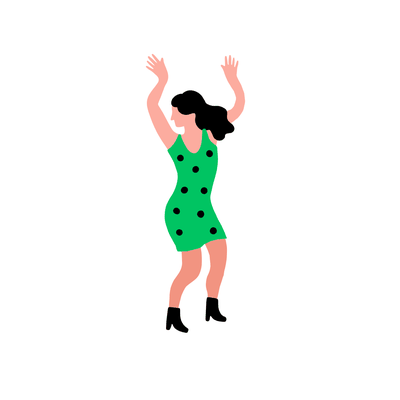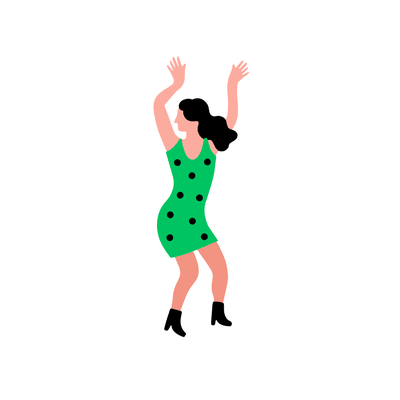
"... dancing."

"... bending arms."

"... jumping."

"... squatting."

"... stomping."

"... waving hands."
We can alter the prompts to generate different movements.
Multi-Layer Animation

Multi-Layer [..]

Single-Layer [..]

Multi-Layer [..]

Single-Layer [..]

Multi-Layer [..]

Single-Layer [..]

Multi-Layer [..]

Single-Layer [..]

Multi-Layer [..]

Single-Layer [..]

Multi-Layer [..]

Single-Layer [..]
High-Order Bézier Trajectory

Cubic Bézier Trajectory (4 points)

Complex Bézier Trajectory (16 points)

Cubic Bézier Trajectory (4 points)

Complex Bézier Trajectory (16 points)

Cubic Bézier Trajectory (4 points)

Complex Bézier Trajectory (16 points)

Cubic Bézier Trajectory (4 points)

Complex Bézier Trajectory (16 points)
Comparisons to T2V Models & Prior Work

ModelScope

VideoCrafter

DynamiCrafter

I2VGen-XL

LiveSketch
Ours

ModelScope

VideoCrafter

DynamiCrafter

I2VGen-XL

LiveSketch
Ours
We compare our method to five baselines: Four Text-to-Video (T2V) diffusion models (ModelScope, VideoCrafter, DynamiCrafter and I2VGen-XL) and LiveSketch.
Ablation Study